
オープンデータを扱ってみよう
~オープンデータによる街のクラスタリング編~
田口 朋晃
株式会社タス
もくじ[非表示]
- 1.はじめに
- 2.データ入手と分析
- 3.クラスタリング結果と考察
- 4.まとめ
- 5.GoogleMapで確認!
はじめに
ここ数年、オープンデータという言葉を耳にする機会が増えたように思います。オープンデータは2013年以降、電子行政オープンデータ戦略に基づき国が推進している取り組みの一つで、以下のような定義があります。
以下、オープンデータ基本指針より抜粋
【オープンデータの定義】
国、地方公共団体及び事業者が保有する官民データのうち、国民誰もがインターネット等を通じて容易に利用(加工、編集、再配布等)できるよう、次のいずれの項目にも該当する形で公開されたデータをオープンデータと定義する。
- 営利目的、非営利目的を問わず二次利用可能なルールが適用されたもの
- 機械判読に適したもの
- 無償で利用できるもの
オープンデータとは、どのようなデータがあるのか、また、何が出来るのかを知っておくことは、社会課題の解決や新たなビジネス創出の観点から非常に重要であるといえます。
今回はオープンデータ活用例紹介の第一段階として、東京23区内の「居住環境が似ている町」を機械学習を用いて分類します。次回以降、似ている町の中から代表的な町を取り上げて、詳細に比較考察していきます。
※町とは以下の通り
「東京都中央区八丁堀3丁目22-13」の「東京都中央区八丁堀」までの部分
データ入手と分析
今回利用するデータは大きく分けて以下の2系統のデータを利用します。これらのデータを機械学習の「クラスタリング」と呼ばれる手法を用いて、似たような町ごとにグループ分けしていきます。また、「似たような町」について、今回は下記のデータのみで定義します。したがって、ここで挙げられていない公園の面積のような要素は考慮しておりません。
① 国勢調査の小地域(町丁目レベル)単位のデータ(5年おきに更新)
- 境界データ
- 面積
- 人口総数
- 世帯総数
- 総数75歳以上
- 世帯人員1人
- 持ち家(世帯数)
- 主世帯数
- 一戸建(世帯数)
- 共同住宅11階建以上(世帯数)
※11階建以上の建物に住む世帯数
② 地価データ(毎年更新)
- 地価公示(ポイント)
- 都道府県地価調査(ポイント)
データの入手と加工
上記①については、総務省統計局のオープンデータ公開サイト「e-stat」より入手できます。今回の対象エリアは東京23区ですので、東京都のデータをダウンロードしますが、この時オープンデータの中では最も細かいレベルとなる小地域単位のデータを選択します。小地域単位のデータを足し合わせていくことで町単位のデータを作成することが可能になります。具体的には各小地域に対して11桁の「KEY_CODE」という一意の番号が振られており、先頭から8桁までをキーにしてグルーピングすることで、町単位のデータを作成しました。
上記②の地価データは、国土交通省のオープンデータ公開サイト「国土数値情報」より入手可能です。こちらは地点の位置情報と価格や用途といった属性情報を合わせた状態で配信されています。前段で作成した境界データと空間的に結合し町内のポイントの平均値を算出し、地価としました。また、町内にポイントが無い場合は、町の境界から半径500メートル以内のポイントの平均値を地価として付与しました。
ここまでの作業で得られたデータをもとに各町に対して以下の説明変数を生成し、さらに人口密度が0である町と地価が得られない町を除外することで、分析用のデータとしました。
※地価平均の算出に地価公示や地価調査を用いた理由は、用途制限や網羅的な地価データ(路線価など)がオープンデータでは入手が難しいためです。もちろん弊社では、数多くの有償データを用いた分析も行っております。
説明変数
- 人口密度(㎡あたり)
- 高齢者割合
- 単身者割合
- 持ち家割合(世帯数より算出)
- 戸建て割合(戸建て世帯数/主世帯数)
- 高層住宅居住割合(共同住宅11階建以上居住世帯数/主世帯数)
- エリアの地価平均(対数)
分析
今回、23区の町を同質の町ごとに分類するにあたって、2種類のクラスタリング手法を段階的に施しています。第一段階は、23区内全ての町を対象として、非階層型クラスタリング手法の一つであるk-means法を用いて4つのグループに分類しました。
次に、分類したグループの内、居住地としての性質がより強いと推測されるグループに対して、階層型クラスタリングのward法を用いてさらにクラスタリングを行いました。2つのクラスタリングの細かい性質については割愛しますが、k-means法は、データの量が多い場合用いられることが多い反面、初期値やクラスタ数の設定など制約の多い分析法であり、ward法は外れ値に強い一方で、データ数が多い場合には向いていないとされる手法です。
クラスタリング結果と考察
まず、はじめのクラスタリング結果からみていきます。各グループの変数の平均値を表1にまとめましたので、この表をもとに考察を行っていきます。結果だけを知りたい方は地図1を参照してください。みなさんの直観に合うような地図になっているでしょうか。
番号1のグループは、他のグループと比較して人口密度が低く、地価平均が高い結果となりました。このことから、居住地ではなくオフィス街のような性質の町が属していると考えられます。
次に、番号2のグループは、2番目に地価平均が高く、概ね番号1のグループに似た値になっています。一方で、人口密度は高いため、住宅地としての性質と番号1のような性質が混在したようなエリアであると考えられます。ここでは、商業地・高級住宅地と表記することにします。
残る2つのグループは、町数が多く、また戸建て割合が高く高層住宅居住割合が低いことから住宅地としての要素が強いと判断しました。さらに、2つのグループを比較したとき、23区平均値に近く、より多くの町が該当しているグループを「住宅地1」、持ち家割合・戸建て割合が高くベッドタウンのような要素を持っていると考えられるグループを「住宅地2」とラベリングしました。
地図1にグループ分けの結果を示します。オレンジで示しているオフィス街を中心として同心円状にグループが構成される結果になりました。商業地については都心5区以外に一部鉄道沿線も点在しています。住宅地については城南・城西と城東で傾向が分かれる結果になりました。
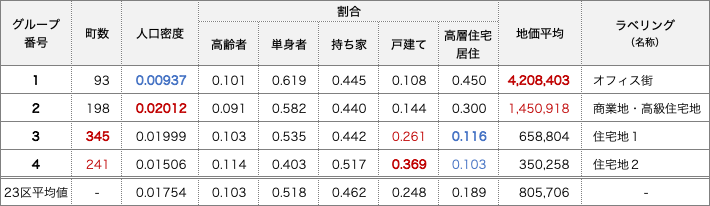
表1:東京23区内の町のクラスタリング結果
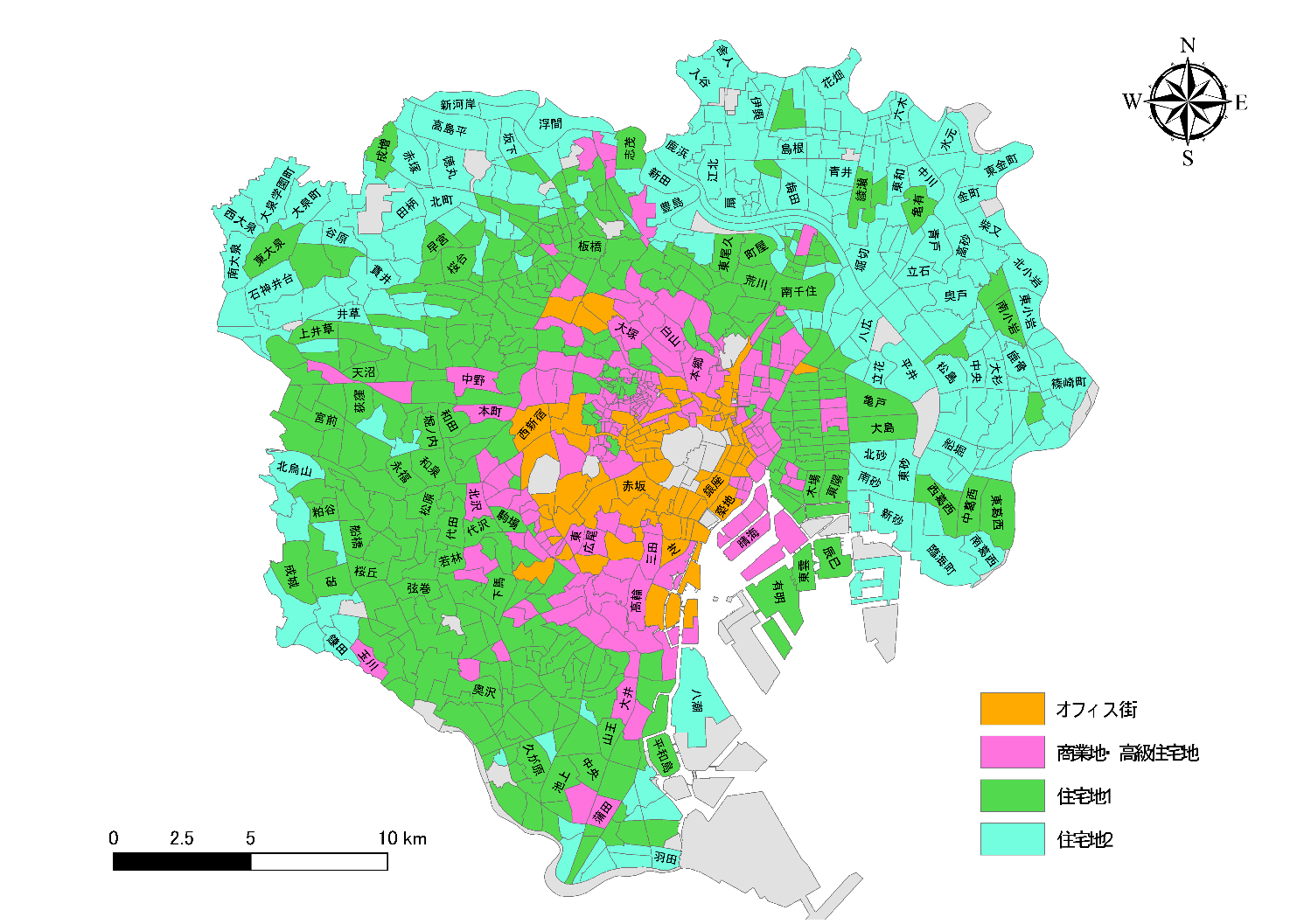
地図1:東京23区内の町の分類
第1段階は、23区を大まかに4つのグループに分けましたが、第2段階は更に細分します。ここでは、対象を地図1内で緑で示されている住宅地1に絞って、ward法でさらに4種類のエリアに分割しました。
各グループの特徴は以下の通りです。グループDについては、持ち家割合と高層住宅割合が最も高く、その一方で、高齢者割合と単身者割合が最も低くなっており、全グループの中でほぼすべての変数で極端な値をとっています。また、地図2をもとに該当の町を調べると公園や大学、鉄道の施設などで大部分を占められているような町が多く、以上2点の理由から特殊エリアと設定しました。
グループAは、地価平均と単身者割合が最も高い一方で、持ち家割合が最も低くなっています。また、都心5区の境界周辺に多く点在していることから居住地としての性質に加えて商業地の特性も併せ持っていると考えられます。
グループBは、Aと同様に、地価平均は全体の平均値と比べ高い傾向にあります。また、他の変数をAと比較すると、持ち家割合・戸建て割合が高く、単身者割合が低くなっており、グループBはAより居住地としての性質が強いといえます。
グループCは、高層住宅居住割合が最も低く、戸建て割合が最も高くなっています。単身者割合や高齢者割合、持ち家割合については平均と近い値となっており、居住地としての性質が強いと考えられます。
次にBとCを比較したとき、Bの地価平均が170千円程度高くなっています。このことからBを「地代が高めの住宅地」、Cを「典型的な住宅地」としました。
第2段階のグループ分け結果を地図2に示します。商業地の要素を持った町が都心に近いエリアに分布しており、それを取り囲むように住宅地が分布しています。中でも地代の高い住宅地は世田谷区に多いようです。
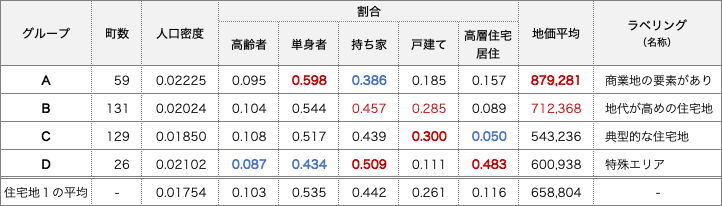
表2:住宅地1のクラスタリング結果
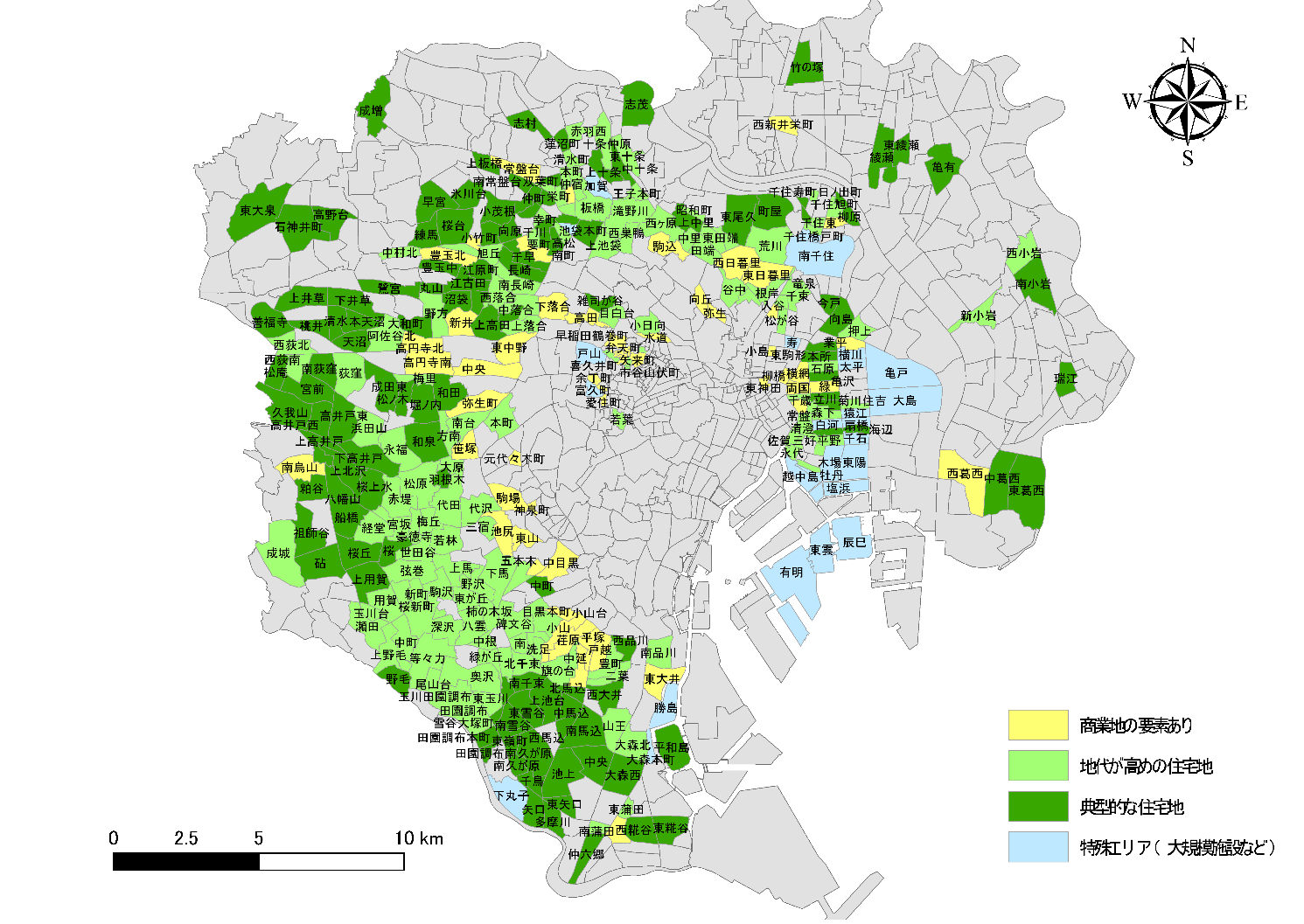
地図2:住宅地のクラスタリング結果
まとめ
今回は試論として、居住地として同質の町を分類することを目的にクラスタリングを行いました。オープンデータのみを用いても、地図と組み合わせることで様々な分析を行うことができました。
次回は、今回の分析結果をもとに、具体的な町を取り上げてより詳細に分析・考察する予定です。
GoogleMapで確認!
参考までに、住宅地のみGoogleMapにオーバレイしました。
気になる町を確認してみてください!
【この記事についてのお問い合わせ】
株式会社タス(https://corporate.tas-japan.com/)
担当:田口
E-mail:column-info@tas-japan.com







